
 iPhone版
iPhone版  Android版
Android版 
有一说一,真不知道这个月是什么情况。
国内的科技互联网厂商们就像扎堆看了同一本黄历一样,都赶着这个月搞事情,各种大模型纷纷上新,给人都看倦了。
而今天,字节跳动的火山引擎也官宣了多个新 AI 模型,其中知危编辑部觉得最惊艳的,就是豆包生成视频模型,效果极其强横。
迟迟不上菜的字节,这一开始上菜就是硬菜。
我们先来看一下官方的演示视频:

这是一条由图片+提示词生成的视频,我们可以看到视频中角色的复杂表情的表现非常自然,发丝的飞舞、马匹头上的棕毛飞舞也很符合物理学,人物在马背上的起伏也很自然。
我们在看这段 “ 骑火箭的男人冲向世界最高城礼堂引发大爆炸 ” 的视频,镜头的移动以及分镜的切换很丝滑,并且画面和画风的一致性保持的很好,中间那个男人紧闭双眼紧张赴死的镜头也很有表现力,画面感拉满了:
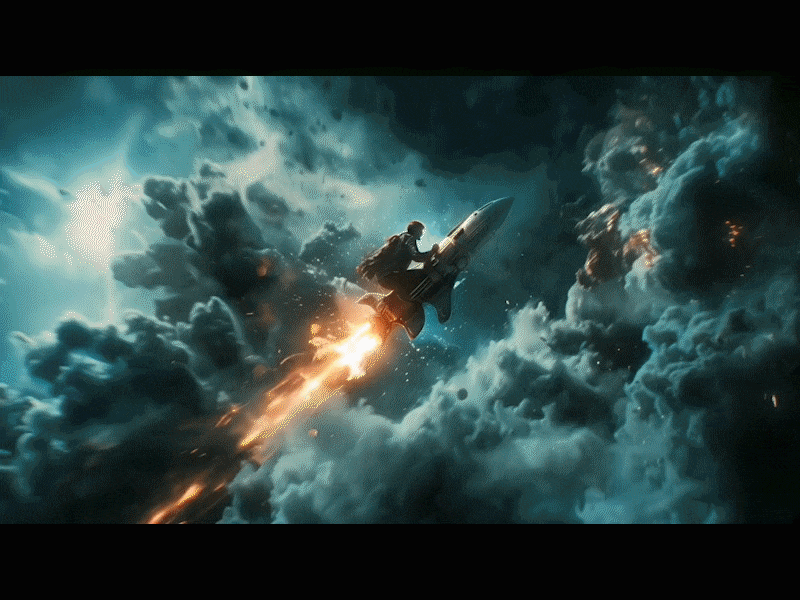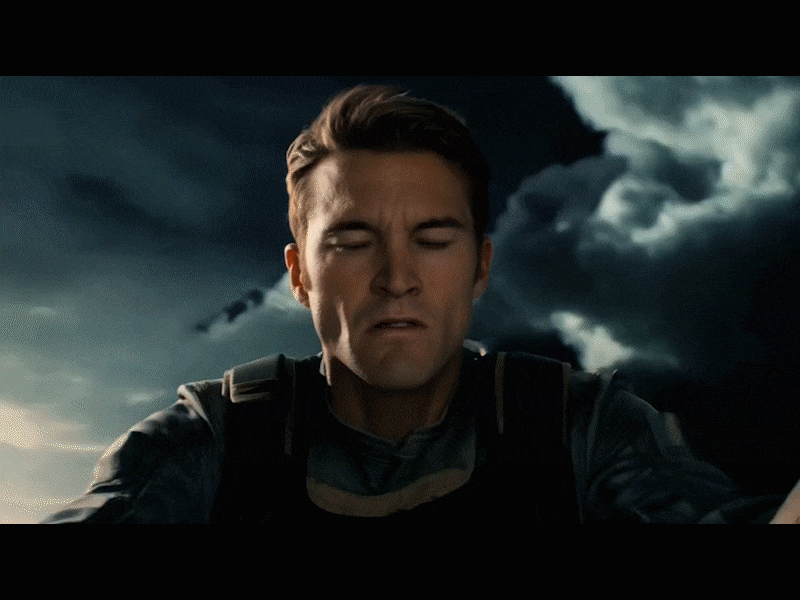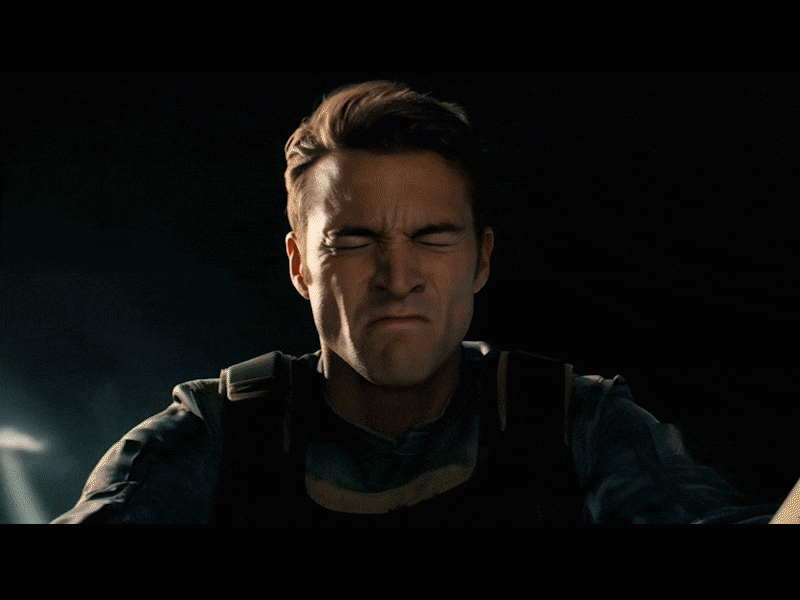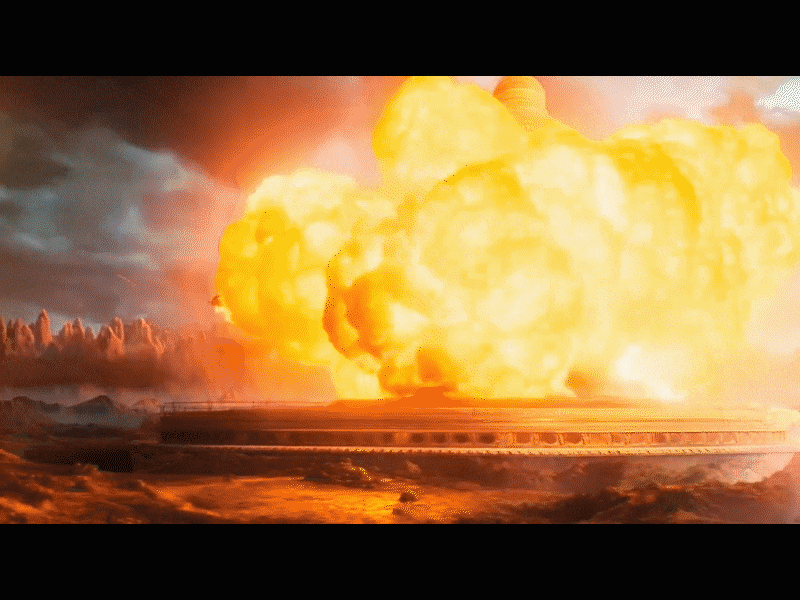
不过,众所周知,AI 行业现在有时候宣传资料就跟方便面外包装一样,看上去是一回事,拆开以后又是另一回事。
所以尽管看完这些演示视频以后我们觉得豆包可能真有两下子,但到底货对不对板,咱还是得上手试一试才知道。
所以,我们找到了字节的朋友,要到了这款模型的内测机会,实测一下它的成色。
模型的名字叫 PixelDance ( 像素跳动 ),暂时只支持图+文输入生成视频,所以我们下面的测试都是基于图+文来进行生成视频。
首先,我们用了一张公司养的金毛的照片:

我们的提示词为:狗狗站起,叼起身边的娃娃离开画面。
看似简单,但是这个需求还是比较难的。因为金毛的脸是被娃娃遮挡住的,让其站起并叼走娃娃,对模型生成的一致性有比较大的挑战,在过往的一些模型测试中,一般狗狗的脸和身材不出 2 秒就会开始崩坏。
但,实际生成的视频是这样的:

这 视频,几乎没有出现太多画面抖动、掉帧和闪烁变形的情况,狗狗起身的动作一气呵成,仔细看它把兔子玩偶拽过来的瞬间,玩偶耳朵会抖动,脚往下踩的时候垫子上也会有凹陷。
也就是说,不仅一致性不错,细节也很好,如果不是狗狗毛发纹理有时有些假,给个 9 分都不过分。
下面,我们才测试一下让不少视频生成模型屡战屡败的光影效果。
我们先是拿豆包文生图功能生成了一张赛博朋克风的骑行照片:

然后再把他丢进了 PixelDance 模型,提示词是:摩托车飞速行驶在道路上,街景迅速后退。
在生成的视频中,街景变化流畅,光线的明暗变化也没违和感,特别是大楼灯光和地面上的倒影都一一对应上了。唯一有点小瑕疵的地方就是从对向开过来的车,画面没太控制好。

随后,我们选取了一张同事吃东西的照片,想测试人物动作的生成:

提示词为:正对镜头的男人张嘴吃下筷子上的食物。
而 PixelDance 模型也确实没让我们失望,拿筷子的动作很熟练,食物是真吃进了嘴里,面部也没有因为咀嚼的动作而变形。即使提示词里没有提到的到后面人群,模型也让他们比较符合日常规律的动了起来,没有什么太大的破绽。
缺点就是,嚼东西的动作有些用力过猛,略显生硬。

其实测到这里,我们对 PixelDance 模型的水平已经有点底了。但为了让测试更全面些,咱还是多试几次。
下面我们来测试奇幻场景,我们提供了一张公司附近的晚霞照片:

提示词为:远处的天空,飞来一条黑色的龙,距离镜头越来越近。
在生成的视频中,画面后面的天空、一排房子、往镜头飞来的黑龙,要素基本齐全,镜头还会慢慢仰拍跟随,但是缺点是龙的质感和飞行动作有些假,导致这条视频是我们认为本次测试里最差的一个案例,这可能跟背后的训练素材的局限性有关。
另外,原本照片左下角应该是桥边的栅栏,不知道是不是因为画面太黑,导致模型没识别出来,小小变形了一下。

最后,我们还测试了一个我们认为难度很高、非常考验一致性和对物理世界规则理解的例子,是一张同事们下班喝酒时拍的照片:

提示词为:大家碰杯后各自拿走自己的酒一饮而尽。
生成的视频中,碰杯导致的液体晃动,手部动作让液体倾斜的物理反馈、杯子的反光等处理的都比较不错。
而且人类手臂的屈伸、关节活动,也比较符合人类生理构造。
而瑕疵则是桌子下的杯垫和下酒小零食有点鬼畜了,右侧一个同事手里的酒似乎喂到了另一个同事嘴里。
总之,有瑕疵,但是瑕不掩瑜,整体来看还是超级惊艳的。
相信看到这,大伙儿心里对豆包这个 PixelDance 模型已经有了基本的评判。
虽说还达不到炸裂的程度,但对比市面上一些效果没那么成熟的模型, PixelDance 模型在画面稳定性、一致性上,确实技高一筹。
在与字节的工作人员的沟通中,他们告诉知危编辑部,为了做出这种接近影视的光影、色彩效果,还用上了剪映这种专门做剪辑和调色的项目的经验。
在此之前,国内的视频模型已经可以说是各方混战打到乱成一锅粥了,而作为拥有中国最好的短视频平台之一的字节却迟迟没有发布相关模型,隔壁快手家的 “ 可灵 ” 都已经有百万用户了。
现在,字节拿出来的 PixelDance 模型,也算是证明了自己,可以说是:
完全值得等,晚些也没关系 。

知危
知危官方正观号



